Blogg

Varför så många initiativ fastnar i pilot – och vad som krävs för att ta dem vidare
Projektgruppen har jobbat intensivt i sex månader. Piloten visar lovande resultat och energin i rummet är hög när presentationen för ledningsgruppen avslutas. Men när alla går tillbaka till sina ordinarie uppgifter händer… ingenting. Tre månader senare ligger rapporten kvar i en mapp, och teamet som drev piloten har gått vidare till nästa satsning.

Tre saker som skiljer organisationer som lyckas styra förändring
Organisationer genomför i dag fler förändringsinitiativ än någonsin. Samtidigt vittnar många om samma utmaning. Det är svårt att hålla riktning, prioritera rätt och få satsningar att leva vidare i vardagen.

ITIL uppdateras nu i en ny generation med det korta och koncisa namnet ITIL, med det interna tillägget version 5. Fokus ligger på att göra ramverket mer praktiskt och flexibelt för hur digitala organisationer arbetar idag.

För snart ett år sedan offentliggjorde vi Cornerstones partnerskap med AI Sweden. Motivet var enkelt: att vara del av ett ekosystem som på allvar försöker förstå hur Sverige ska bygga AI-kompetens, inte bara i enskilda organisationer, utan som nation.

När vi nu blickar tillbaka på våra omfattande Generativ AI-satsningar under det senaste året, står det klart: Sverige befinner sig mitt i ett paradigmskifte. Men vägen dit ser annorlunda ut än vad många trodde.
Cisco uppdaterar sina certifieringsspår, som får en tydligare och mer konsekvent namnstruktur. Här får du en tydlig sammanfattning av vad som händer, när det händer, hur du påverkas och vad just du behöver göra.

Windows Server 2025 är den största uppdateringen av Windows Server på nästan ett decennium. På Cornerstone ar vi tagit fram ett brett och heltäckande spektrum av av kurser som snabbt får dig på banan med den senaste tekniken.

Ledarskap handlar inte om perfektion. Det handlar om modet att utvecklas.
Ingen föds som färdig ledare – men alla kan välja att bli bättre.
Här guidar vi dig genom fem avgörande egenskaper som bygger starka ledare – baserade på forskning, erfarenhet och verkliga berättelser från arbetslivets vardag.

Vår senaste undersökning avslöjar ett oroande gap mellan teknologisk ambition och kompetensberedskap inom svenska organisationer. Det vittnas om brister i beredskap, strategi och budget, men även bristande samarbete mellan HR
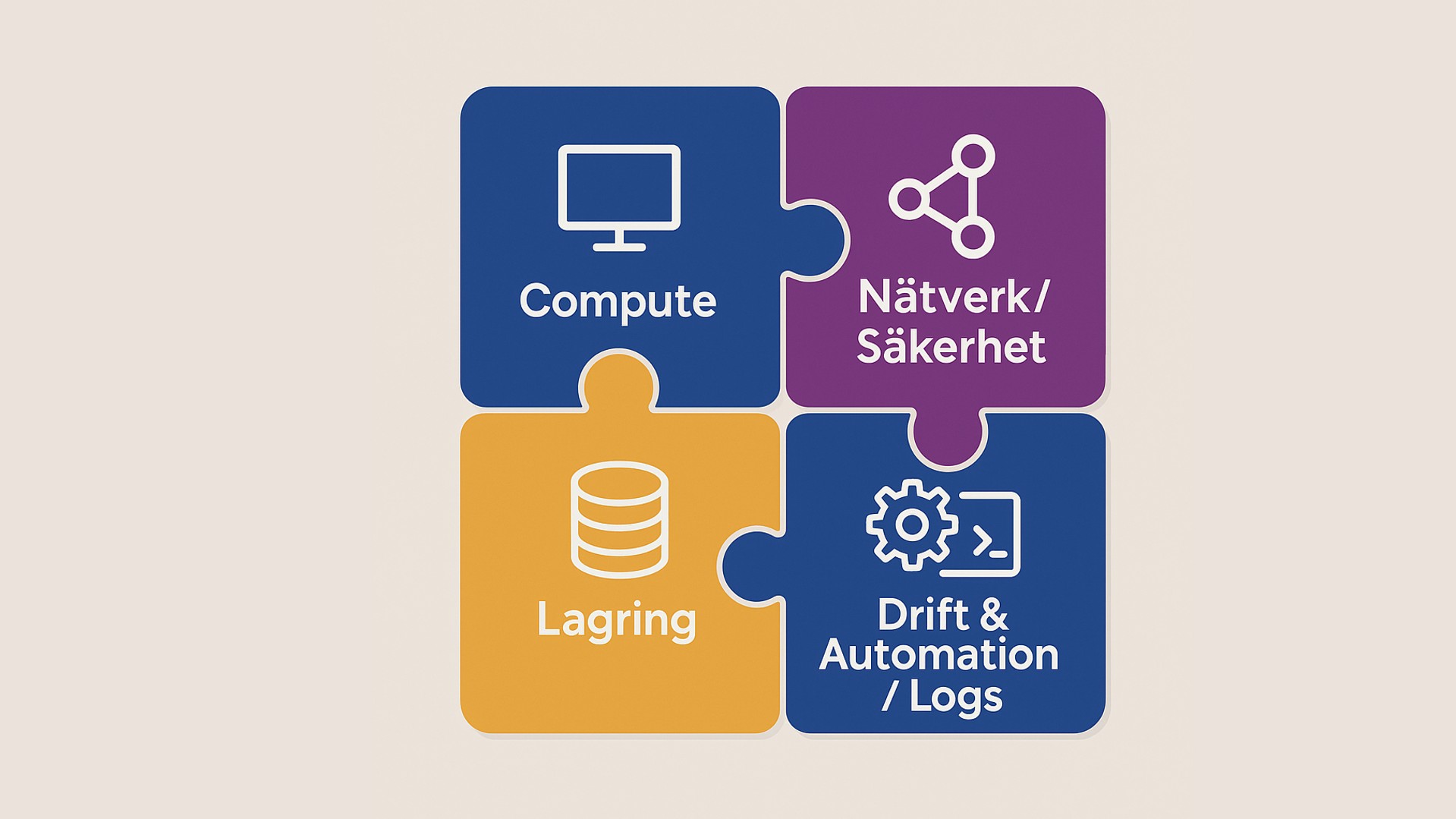
VCF 9 är Broadcoms plattform för privat moln – inte bara ”vSphere + NSX”, utan en sammanhållen stack med gemensam installation, drift och livscykel. Här är en enkel vägledning och kursöversikt för dig som arbetar med VMware-teknologier.

I takt med att digitaliseringen accelererar ställs allt högre krav på att verksamheter kan utveckla och förändra sina IT-lösningar snabbt — utan att tappa helhetsbilden. Här blir Enterprise Architecture (EA) en avgörande faktor, och i centrum står ett ramverk som i över 25 år hjälpt organisationer världen över att skapa struktur i komplexitet: TOGAF®.

NIS2 ställer krav, men också frågor. Vilka teknologier stöttar de olika säkerhetsprinciperna? Och vilka kunskaper behöver teamet för att faktiskt genomföra åtgärderna?
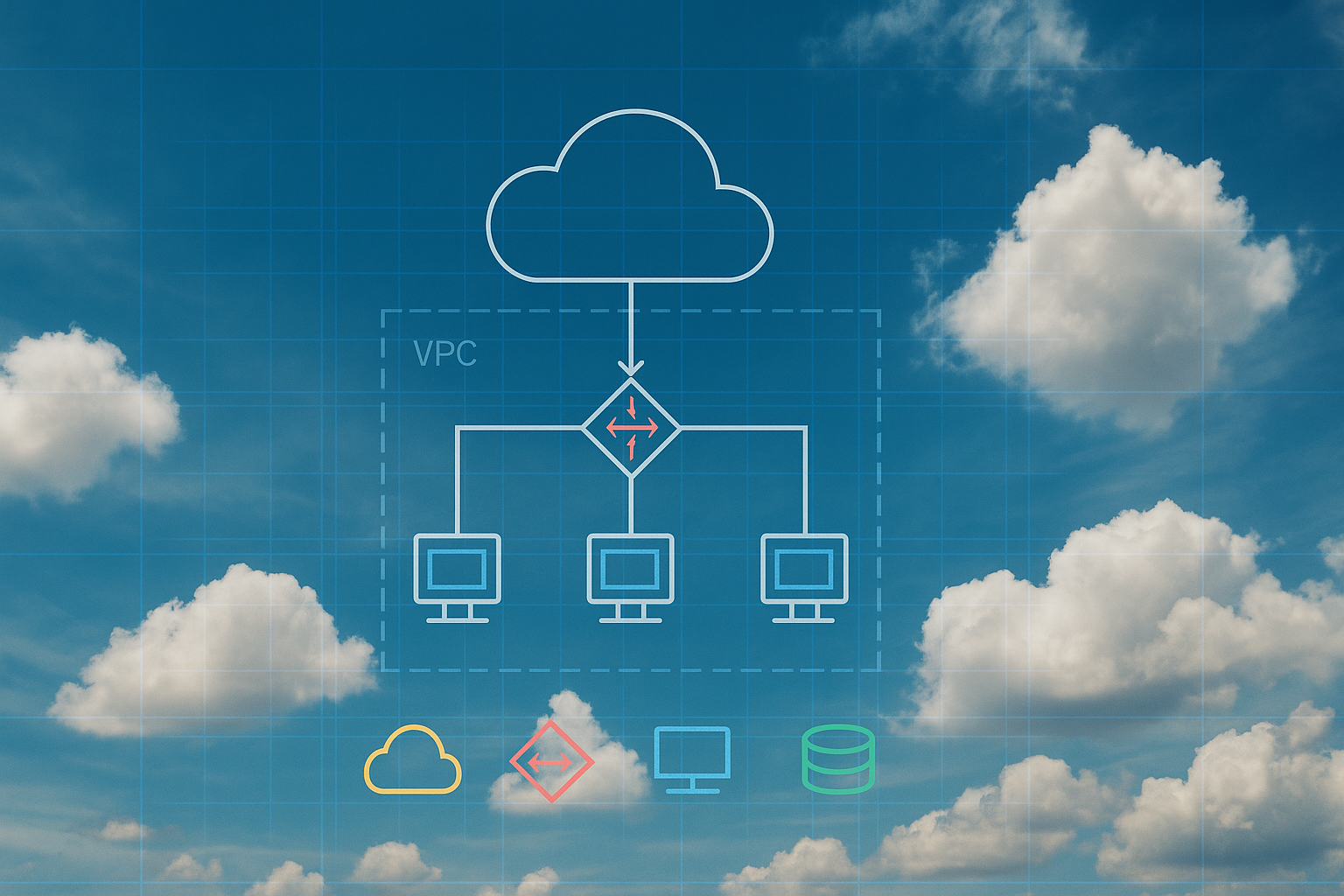
Att arbeta effektivt i Google Cloud Platform (GCP) kräver både förståelse för plattformens grundläggande byggstenar och praktisk förmåga att designa, drifta och skala lösningar. Cornerstone erbjuder ett sammanhållet kursutbud som tar dig från introduktion till arkitektur och produktion – i din takt och på det sätt som passar din verksamhet.

ITIL Foundation är ofta startpunkten – men hur väljer du rätt fortsättning? Med tre tydliga certifieringsvägar inom ITIL 4 avgör du om du vill fördjupa dig i leverans, strategi eller praktiker och därmed stärka både din karriär och din organisations förmåga.

Är du osäker på vad alla Microsofts AI-verktyg egentligen gör – och vilket som passar dig? Du är inte ensam.

På Cornerstones webb har vi samlat webinar, artiklar och utbildningar som guidar dig från grundläggande begrepp till praktisk tillämpning i vardagen.

Nu smalnar vägen av för den som vill fortsätta med Exchange Server och inte gå över till molnbaserad messaging. I juli lanserades Exchange Server med prenumerationslicens, och innan årets slut är detta den enda supportade On Premise-versionen.

På Cornerstone hittar du gott om specialiseringar inom olika Azure-teknologier, och din förmåga byggs allra stadigast på en bas av generell kompetens i hur plattformen fungerar - Hur dess komponenter samspelar, hur tjänster hänger ihop och hur Azure verkligen lever och andas i praktiken.

Möten tar tid – och för många chefer utgör de en stor del av vardagen. När upp till 70 % av arbetstiden går till möten blir effektivitet avgörande – för både resultat och arbetsmiljö. I en tid av digitala och hybrida möten ökar kraven på att de faktiskt leder någonstans. Här får du fem konkreta tips för att göra dina möten mer engagerande och produktiva.

Att ta klivet in i chefsrollen för första gången är ett av de största och mest omvälvande stegen du kan ta i din karriär. Plötsligt är det inte längre bara dina egna prestationer som räknas – utan din förmåga att lyfta och leda andra.

Att tala inför en grupp kan kännas skrämmande – oavsett om publiken består av fem kollegor eller hundra främlingar. Men här är den goda nyheten: presentationsteknik är ingen medfödd gåva, utan ett hantverk du kan träna upp. Precis som vilken färdighet som helst kan du bli bättre med rätt verktyg och träning.

AI förändrar spelplanen för både angripare och försvarare inom cybersäkerhet. För att hänga med krävs mer än traditionell kunskap – det krävs taktisk kompetens, praktisk färdighet och förståelse för hur AI kan förstärka både analys och attack.

Nu erbjuder Cornerstone en ny kurs inom Azure Integration Services - en modern ersättare för BizTalk Server.

Cornerstone Group och Microsoft presenterar AI Skills Fest – en unik möjlighet att delta i en inspirerande resa in i framtidens teknik! Under 50 dagar, med start den 8 april, har du chansen att fördjupa dig i en värld av artificiell intelligens (AI) tillsammans med Microsoft och ledande branschexperter.

Nu lanserar vi en rykande färsk Windows Server 2025-kurs där virtualisering, klustring och lagring står i fokus – fundamentala teknologier som bär moderna datacenter på sina axlar.

I en värld där cyberhot ständigt utvecklas är det avgörande att ha full kontroll över vilka applikationer som får köras i din IT-miljö. Nu lanserar vi en kurs för IT-proffs som jobbar med hantering av Windows-baserade endpoints i en modern management-miljö.

Nya globala data från LinkedIn visar att nästan 3 av 5 medarbetare (58%) planerar att söka nytt jobb under 2025. I samma undersökning framgår att hälften av de arbetssökande upplever att jobbsökandet blivit svårare det senaste året. Detta skapar både utmaningar och möjligheter för organisationer som vill behålla och utveckla värdefull kompetens.
I takt med att AI och automation förändrar IT-servicens landskap, blir mänskliga färdigheter allt viktigare. Medan teknisk kompetens fortfarande är avgörande, visar forskning från Harvard Business Review att upp till 85 % av utvecklingsbehovet i moderna serviceorganisationer handlar om relationsskapande och samarbetsförmåga.

Med ITIL Foundation har du en stark grund inom IT-tjänstehantering. Men för att behålla skärpan och fortsätta utvecklas kan du enkelt fördjupa dig inom de områden som är mest relevanta för din roll. Här kommer våra korta specialiseringskurser väl till pass.
Moderna organisationer behöver ett effektivt och målinriktat lärande. Med utgångspunkt i 5 Moments of Need-metodiken optimerar vi balansen mellan formell utbildning och lärande i arbetsflödet. Genom att fokusera formella lärtillfällen där de ger störst effekt, och flytta mer stöd och utveckling direkt in i arbetsprocesserna, skapar vi en kontinuerlig kompetensutveckling som ger bestående resultat

Microsoft Intune har blivit en central komponent i modern desktop management, och nu kan du ta nästa steg i att utnyttja potentialen hos Intune.

Som HR-ledare står du inför en spännande möjlighet – att forma framtiden för din organisation genom strategiska kompetenssatsningar. I en värld där den digitala transformationen snabbt förändrar arbetslivet har du chansen att ta täten och förbereda din organisation för morgondagens utmaningar.

Kista, 20 januari 2025 – Cornerstone, en ledande aktör inom kompetensutveckling och utbildning i Sverige, meddelar med stolthet sitt nya partnerskap med AI Sweden – Sveriges nationella centrum för artificiell intelligens.

I dagens snabbt föränderliga arbetsliv har hybridarbete – en kombination av distansarbete och kontorsnärvaro – blivit det nya normala för många. Denna flexibilitet ger frihet och självständighet, men ställer också högre krav på var och en att ta ansvar för sitt eget arbete och utveckling. Här på Cornerstone ser vi hur självledarskap har blivit en avgörande förmåga för att lyckas i en hybrid arbetsmiljö.

Nu utökar vi vårt Linux-erbjudande med ytterligare kurser i felsökning, problemlösning och avancerad Enterprise-funktionalitet.

Som tech-rekryterare står du inför en spännande utmaning: att överbrygga klyftan mellan tekniska kompetenskrav och tillgängliga talanger på en alltmer komplex arbetsmarknad. Låt oss tillsammans utforska hur du kan utveckla din förståelse för tekniska roller och stärka din position som strategisk partner i rekryteringsprocessen!

Har du investerat i en egen lärarledd utbildning för dina kollegor? Grattis till en god investering! Nu vill du förstås få ut maximal effekt och ROI av insatsen, och då finns det flera faktorer du själv kan påverka.
Ämnesexperten Joachim visar hur du i Microsoft Teams kan konvertera en konversation till en uppgift i Planner.

Minska klickande genom att använda kortkommandon när du arbetar i Microsoft Teams

Vår ämnesexpert Joachim visar hur du gör dig redo för semestern genom att stänga av den automatiska hämtningen av e-post i din telefon.

Sitter du med de där sista förberedelserna inför semestern? Låt vår ämnesexpert Joachim visa hur du snabbt och enkelt ställer in autosvar i Teams och Outlook!
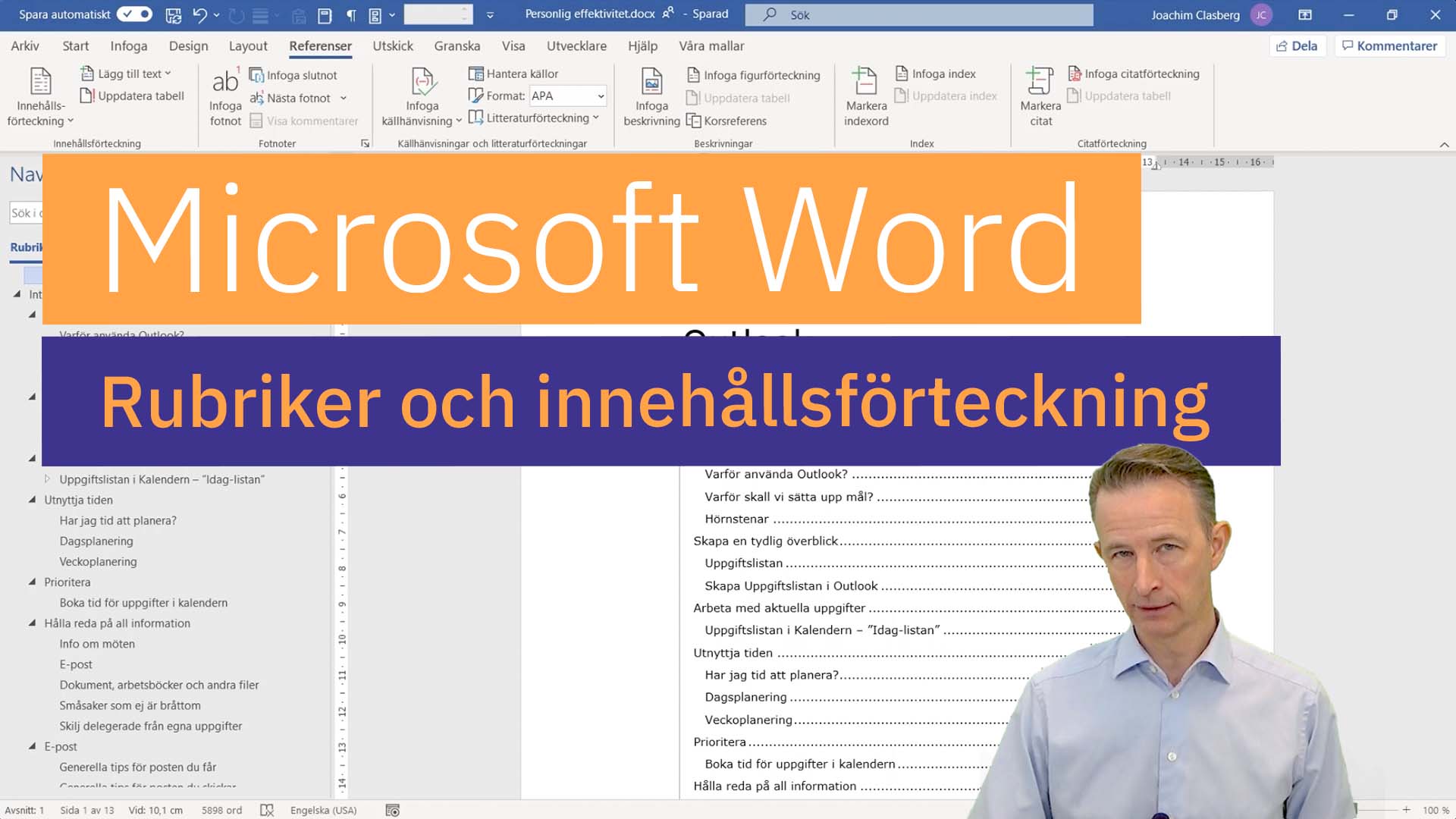
Vår ämnesexpert Joachim Clasberg visar hur du skapar rubriker och innehållsförteckning i Microsoft Word.

Vår ämnesexpert Joachim Clasberg visar hur du använder live undertext i ett Microsoft Teams-möte

Vår expert inom Microsoft Office Joachim Clasberg lär dig snabbt och enkelt hur du i Microsoft Teams samlar möten i en kanal för att enkelt komma åt till exempel filer, deltagarrapporter och anteckningar.

Det senaste och kanske mest framgångsrika försöket att kombinera simplicitet och effektivitet inom projektmetodik stavas Modern Agile. I fokus står kunden, konsumenten, medarbetarna och resultaten, och vore inte det tillräckligt så går det smidigt att integrera i redan befintlig projektmetodik. Äntligen har vi ett modernt och agilt arbetssätt som sticker ut, är enkelt att använda och som passar alla sorters projekt.
Det enorma behovet av förändring för att leverera värde till kunder med mindre resurser, ökad hastighet och kvalitet vid rätt tidpunkt är en sanning. Konsekvenser av att misslyckas med omställningen är lika stora som effekterna av att lyckas för både verksamhet och människa.

Vad vet du om Lean portföljhantering (Lean Portfolio Management)? Varför det är viktigare och viktigare för hela organisationen att vara agil, inklusive ledningen? Se vårt populära webinar med Ola Gedenryd och Jörgen Karlsson

Sedan länge vet vi att demografin förändras och att antalet äldre kommer att öka markant i Sverige. Vi vet därmed också att det inom en snar framtid kommer att bli en rejäl utmaning att klara behovet av vård och omsorg.

Att se till att anställda och partners får tillgång till rätt saker är en viktig uppgift för alla företag. Det påverkar produktiviteten direkt. Likaså är det en viktig uppgift att se till att tillgången tas bort när det inte längre är motiverat att den skall vara kvar. Det påverkar säkerheten direkt. Idag när vi oftast arbetar på distans så kan det här vara svårt att åstadkomma.

Genom att köra dina Windows-datorer anslutna till endast Intune kan du göra livet enklare för dina användare i verksamheten men också underlätta för de som hanterar plattformen under hela enhetens livscykel.

Vår ämnesexpert Joachim visar hur du förvandlar Excel-listor till interaktiva rapporter.

Det sker just nu stora förändringar i sättet att se på organisering och ledarskap. Det pågår en rörelse ifrån traditionella hierarkiska strukturer till att i stället gå mot flexibla, snabbfotade arbetssätt. Där fokus ligger på ledarskap hos alla och att distribuerat beslutmandat.

Vad är det som gör att så många inte får ut de effekter som ett införande av DevOps faktiskt kan leda till, både för de som arbetar med DevOps och för hela verksamheten? Varför är DevOps bra? Vilka är framgångsfaktorerna? Tre mycket kloka frågor att besvara i tid för att undvika kostsamma fallgropar till förmån för en effektfull transformation och investering.
För att effektivisera samarbetet i Microsoft Teams och Outlook kan du integrera verktygen, skapa tydliga uppgifter och använda kanaler för att organisera kommunikationen. Genom att optimera e-posthanteringen och dela filer effektivt kan arbetsflöden förbättras och onödig kommunikation undvikas.

Att hantera dubbletter i Excel är avgörande för att upprätthålla ordning och noggrannhet i dina data. Oavsett om du kopierar och klistrar in information från olika källor eller bearbetar stora mängder data, finns det verktyg och metoder som kan underlätta processen.

Sedan starten 2011 har Scaled Agile Framework, SAFe, kontinuerligt uppdaterats baserat på återkoppling från organisationer över hela världen. Kontinuerlig förbättring är basen inom Lean och även det som gjort SAFe till det ledande storskaliga ramverket. Till skillnad från version 5.0 är version 6.0 bakåtkompatibel och tonvikten ligger på att förstärka grundläggande koncept och göra dem mer tillgängliga. Varje artikel i ramverket har uppdaterats för att förbättra tydlighet och förståelse.

Efter att Citrix Systems gått samman med Tibco och bildat Cloud Software Group används namnet Citrix bara på vissa av de produkter som tidigare gått under det namnet. Här kommer en sammanfattning av hur det ser ut och hur det påverkar vårt kursutbud.

Låt oss börja med att skilja på begreppen metodik och metod. Metodik kan sägas vara ett samlingsnamn för en uppsättning av metoder, sätt att arbeta på för att skapa ett eller flera önskade effekter/värden. En enskild metod beskriver ett specifikt tillvägagångssätt, ett sätt att arbeta på för att skapa värden.

Under mina många år ute bland organisationer har jag kommit fram till två nyckelkompetenser som möjliggör ett kommunikativt ledarskap – kommunikation och emotionell intelligens. Man talar om detta som två olika kompetenser och ändå är de så sammankopplade.

Det nya arbetslivet kräver flexibla och snabbfotade arbetssätt, där teamutveckling spelar en central roll. Vi rör oss bort från hierarkiska strukturer och mot en kultur där beslutmandatet fördelas och alla bidrar till ledarskapet. Men hur skapar vi effektiva och hållbara team som möter framtidens utmaningar?

Självledarskap handlar om att ta kontroll över din egen resa, fatta beslut och navigera genom hinder på vägen mot dina mål. Det är din nyckel till att skapa motivation, ansvar och framåträtta.

Har ni råd att inte investera i effektivitet? På Cornerstone har vi genom åren sett tydliga bevis på hur rätt kompetensutveckling inte bara förbättrar vardagen – den skapar konkret affärsvärde. Särskilt påtagligt är detta inom Microsoft 365, där våra senaste uppföljningar visar anmärkningsvärda resultat: Efter genomförd utbildning ökar medarbetarnas effektivitet i arbetet med verktygen med hela 62%

Varför är det så många organisationer som inte får ut de fulla effekterna av en DevOps-transformation? Hur kan både de som arbetar med DevOps och verksamheten som helhet dra nytta av dess fördelar? Och vad är de viktigaste framgångsfaktorerna? Dessa frågor måste besvaras i tid för att undvika kostsamma fallgropar och maximera avkastningen på en sådan investering.

Hälsostrategiska ledare och verksamheter som satsar aktivt på företagshälsovård vinner i längden. Frågan är: har du viljan, orken och förmågan att vara en hälsostrategisk ledare ”här och nu” och i framtiden?

Intervju med Niklas Laudon från Cornerstone

Har du tappat motivationen på jobbet? I denna artikel får du tre konkreta verktyg för att hitta tillbaka till din energi och drivkraft. Lär dig hur du kan stärka din egen motivation och hur du som ledare kan skapa en arbetsmiljö som inspirerar både dig själv och ditt team att nå nya mål.
Att se till att anställda och partners får tillgång till rätt saker är en viktig uppgift för alla företag. Det påverkar produktiviteten direkt. Likaså är det en viktig uppgift att se till att tillgången tas bort när det inte längre är motiverat att den skall vara kvar. Det påverkar säkerheten direkt. Idag när vi oftast arbetar på distans så kan det här vara svårt att åstadkomma.

Vad hände? Vad var det som kraschade? Vad hände innan? Tillförlitlighetsövervakaren, mer känd under sitt engelska namn Reliability Monitor, fungerar som en dagbok över vad som hänt på din dator flera månader tillbaka.
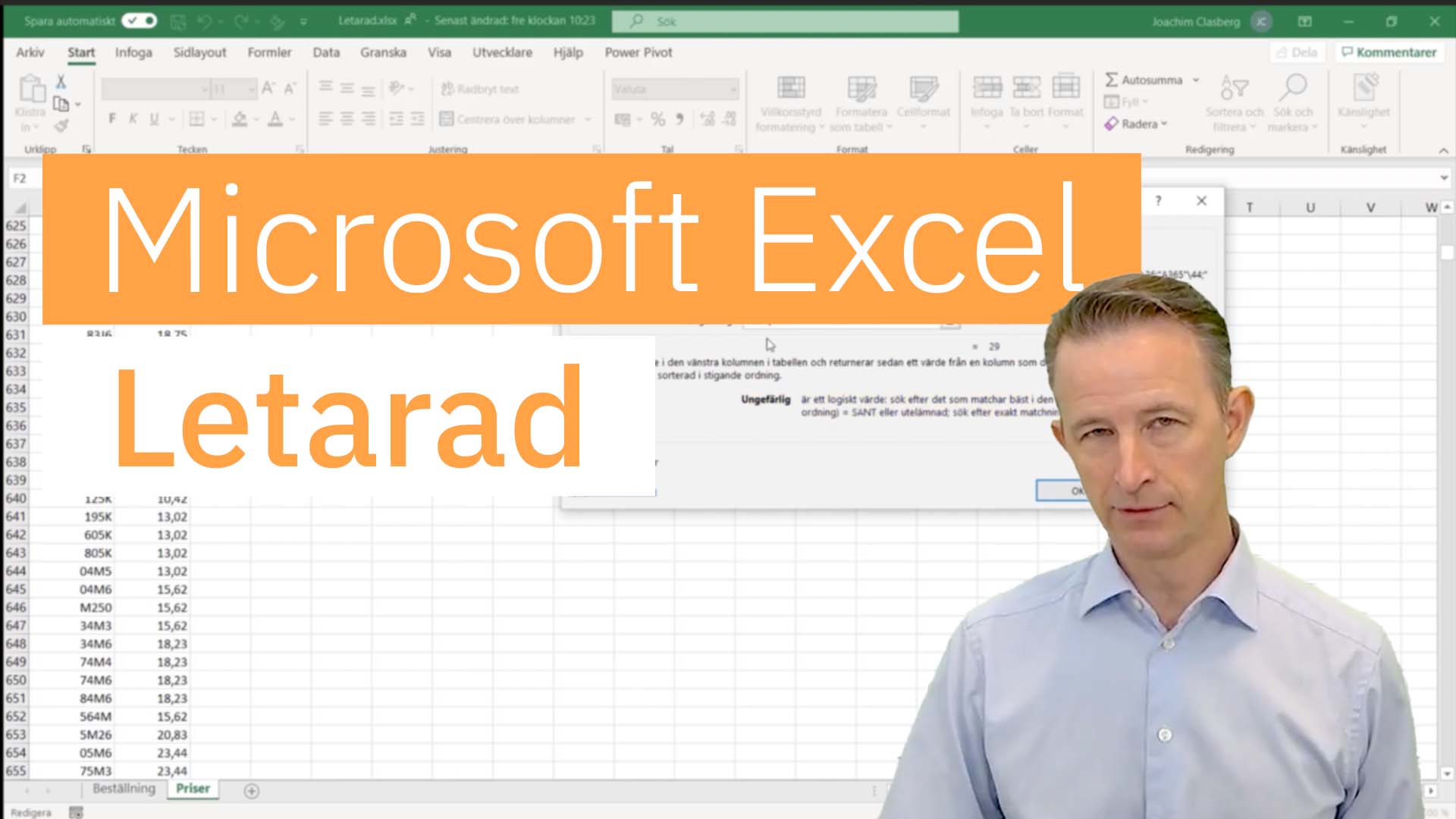
Ämnesexperten Joachim Clasberg visar hur du använder dig av funktionen Letarad i Microsoft Excel.

Vår ämnesexpert Joachim visar hur du förvandlar Excel-listor till interaktiva rapporter.